Available Projects
The following projects are suitable primarily for strong undergraduate graduates, either as Honours Thesis projects or in groups for their design projects, often working in conjunction with graduate students in our lab. Team descriptions are based on the assumption of these being undertaken by undergraduate students. Please read the FAQ and then contact me if you are interested in getting involved in any of these projects.
Electrical and Computer

Internet Multimodal Access to Graphical Exploration (IMAGE) is a project aimed at making internet graphics accessible for people who are blind or partially sighted through rich audio and touch. On the internet, graphic material such as maps, photographs, and charts are clear and straightforward to those who can see it, but not for blind or low-vision users. For them, graphical information is often limited to manually generated alt-text HTML labels, often abridged, and lacking in richness. This represents a better-than-nothing solution, but remains woefully inadequate. Artificial Intelligence technology can improve the situation, but existing solutions are non-interactive, and provide a minimal summary at best; the essential information described by the graphic frequently remains inaccessible. Our approach is to use rich audio (sonification) together with the sense of touch (haptics) to provide a faster and more nuanced experience of graphics on the web. For example, by using spatial audio, where the user experiences the sound moving around them through their headphones, information about the spatial relationships between various objects in the space of the graphic can be quickly conveyed without reading long descriptions. In addition, rather than only passive experiences of listening to audio, we allow the user to actively explore a graphic either by pointing to different portions and hearing about its content or nuance, or use a custom haptic device to literally feel aspects like texture or regions. This will permit interpretation of maps, charts, and photographs, in which the visual experience is replaced with multimodal sensory feedback, rendered in a manner that helps overcome access barriers for users who are blind or low-vision. Our technology is designed to be as freely available as possible, as well as extensible so that artists, technologists, or even companies can produce new experiences for specific graphical content that they know how to render. If someone has a special way of rendering stock market charts, they do not have to reinvent the wheel, but can create a module that focuses on their specific audio and haptic rendering, and plug it into our overall system. Our deployed, open-source web browser extension is already in use, and we are presently working toward the addition of support for mobile (smartphones). The next steps of this project will involve augmention of the architecture to support interactive human-in-the-loop content authoring of audio-haptic experiences and leveraging of new preprocessor capabilities based on AI advances in the realm of image-ingest capabilities of GPT-4 and beyond. Additional potential areas for students with specific interests/skills:
- Working to enable/create experiences on haptic devices, including the Humanware Monarch and the Haply 2diy.
- Using GPT/LLM techniques to create audio/haptic experiences for new data types or user scenarios (e.g., sonifying product photos from retail websites, expanding the maps and charts for which IMAGE can successfully create renderings, etc.)
- Working in the IMAGE browser extension to refine methods for selecting desired graphics
- Integrating IMAGE into Drupal
- Creating a library of sonification effects in SuperCollider, easily usable by developers creating audio effects for end-user renderings
- Integrating IMAGE directly into the NVDA open-source screen reader
- Working with external groups and creating documentation to help integrate their code into the IMAGE code base
- integrate the services of our Autour server with the queries currently being made to OpenStreetMap
- dockerize the Autour server
- extending our preprocessors for new types of maps
- exploring haptic renderings for diagrams and similar textbook materials
- exploring other commercial ML tools that could be used to extend/improve our existing preprocessors, e.g., scene recognizer
In addition, we have positions available involving:
- using web programming to design and implement UI features for our Chrome extension; these UI components for our Chrome browser extension include user-configurable settings windows, layout of dialog and message boxes, and, as an added challenge, must be screenreader accessible as well as functional and attractive.
- conducting a variety of user studies related both to these developments and other aspects of the system, and analyzing the results
This project is ideal for student(s) with an interest in user interface design, user research, and HCI.
 CyberSight
CyberSight
Blind and visually impaired (BVI) individuals often find the shopping experience to be inaccessible. A variety of applications and tools have been created to address aspects of these problems, and AI technology continues to improve for identifying objects and text. However, gaps remain, in particular, necessary functionality such as locating specific articles, reaching for them on the shelf, verifying that they have acquired the desired item, and obtaining pricing information. At present, for those in the BVI community, these tasks generally involve reliance on the assistance of others.
This project will develop technology that supports acquisition and verification of a desired object once the user is situated in a limited radius of the target item, so that it can be seen by a smartphone camera from that position. This will involve dynamically directing the user to reach the object, verifying that the intended item has been acquired, and providing desired product information such as ingredient listings or price. The technology is intended to run on commodity smartphones, potentially in conjunction with bone conduction headphones for auditory display.
The tasks that this project aims to support include:
- Scan the scene in a predefined zone in front of the user with the mobile device camera to find a desired object
- Locate using computer vision and AI/ML techniques, the position of the object, e.g., on the shelf
- Interact with the environment, while tracking the user's hand, to provide autonomous guidance to help the user to grab or approach the desired object using real-time audio and/or haptic feedback
- Validate that the desired object has been acquired through text-to-speech information obtained from the specific item, e.g., the product label
In this manner, assuming deployment of a suitable pre-existing localization technology to guide the user to within a small radius of the desired object, our objective is for the system to guide the user to reach desired objects, and then verify specific information, for example, using computer vision, optical character recognition, and generative pretrained transformers.
 Transforming speech into vibrations: Development of a wearable vibrotactile device to support communication of people who are hard of hearing or deaf
Transforming speech into vibrations: Development of a wearable vibrotactile device to support communication of people who are hard of hearing or deaf
We are developing a vibrotactile apparatus that converts speech audio into vibrations delivered on the user's skin. Previous research conducted by our lab and other researchers has proposed various designs and language encoding strategies. These studies have demonstrated the effectiveness of these approaches in enabling individuals without hearing loss to comprehend complex vocabulary solely through vibrotactile stimulation. However, there has been little research exploring the benefits of multimodal fusion to interpretation of speech for deaf or hard-of-hearing individuals, and the research that has been conducted for unimodal (haptic) sensory substitution with this community has been limited to pilot studies employing a simplistic vocabulary (50 single-syllable words), with testing trials presenting four options from which the user could choose.
Our goal is to design such devices specifically for people with hearing loss, actively involving them in the design process, and evaluating their communication performance in real-world scenarios. The research project focuses on several specific topics, including:
- Designing novel discrete haptic encodings for vibrotactile communication systems tailored to individuals with hearing loss. This will be achieved through a participatory design approach that actively engages the users in the design process.
- Investigating the different types of support that haptic language systems should provide in various communication contexts. These contexts may include face-to-face interactions, asynchronous communication through messenger apps, and human-computer conversations (e.g., receiving communication from voice assistants).
- Exploring the effects of combining haptic delivery of speech with lip reading on the speech comprehension of individuals with hearing impairments. This research aims to understand how the integration of haptic feedback and visual cues can enhance the overall comprehension and communication experience for people with hearing loss.
We are seeking motivated students who have a background in computer science or computer engineering, along with familiarity in signal processing and strong programming skills. Eagerness to learn and a problem-solving mindset are essential. Experience with any of the following: digital audio workstations (DAW) such as Ableton, natural language processing (NLP) techniques, and the Flutter toolkit, would be considered assets.
During the project, students will work closely with graduate students and a postdoctoral fellow,
designing a set of vibrotactile stimuli that maps different letters or phonemes to a distinct vibration
pattern. This includes applying signal processing techniques on a digital audio workstation (DAW) or
through Python libraries. The student will also work on implementing the software needed to run the
user training and testing. This may include modifying the existing code (Dart/Flutter) or creating new
applications. The student will have the opportunity to contribute with their insights and opinions during
the system development and testing, and participate in co-authorship of an intended research
publication.
 Generative Augmented Reality Art Therapy for Patients Experiencing Chronic Pain
Generative Augmented Reality Art Therapy for Patients Experiencing Chronic Pain
For many patients suffering from chronic pain, it is difficult to express how their pain feels in words. This project will develop a tool to allow patients to collaboratively illustrate their pain experience in communication with their doctor. In this regard, art therapy has long been a tool that allows such individuals to work through their pain in a physical way and better communicate with their healthcare team. However, for many, expressing themselves effectively through the creation of art is a daunting process. By creating an augmented reality tool, leveraging generative networks that helps in this process, patients will gain a way to benefit from the art therapy paradigm without requiring artistic skills. At a high level, the fundamental tasks the student(s) will undertake include:
- Potentially assisting in the creation of one or more data sets suitable for training the generative models
- Choosing an appropriate toolset for developing a virtual environment
- Developing a basic virtual environment through which a patient and doctor can interact
- Adding virtual "art tools" that patients can use to draw on their own virtual avatar
This project is suitable for a group of motivated students with experience or strong interest in augmented and/or virtual reality, and the applications of machine learning techniques.
 Vision-guided Navigation Assistance for the Visually Impaired
Vision-guided Navigation Assistance for the Visually Impaired
This project aims to leverage the benefits of smartphones, possibly carried on a neck-worn lanyard, or connected to external devices such as head-worn panoramic camera systems, to provide navigation assistance for the visually impaired community,
- safely guiding users during intersection crossing to avoid veering, which can be dangerous and stressful
- helping them navigate the last few meters to doorways they wish to enter
- directing them to important points in the environment such as stairways and bus shelters
- switching between different app services, including navigation functions such as those listed above, and other services including OCR, product identification, and environment description, based on contextual information and personalization.
Our proposed approach combines a machine learning strategy leveraging existing image datasets, possibly augmented by crowdsourcing, and iterative design of the feedback mechanisms. This is informed by our lab's experience with sensor-based intersection-crossing assistance systems, and in developing the Autour app, which provides a real-time description of street intersections, public transport data, and points of interest in the user's vicinity.
Students should have experience in machine learning, mobile software development, and interest in assistive technologies.
 Musical Telepresence
Musical Telepresence
Videoconferencing technology allows for effective interaction, as long as everyone remains in front of their computer screen (and camera), and is willing to accept a stationary 2D view of their counterparts. However, as we have all experienced from the years of the pandemic, this is not the same as being together "in the real world", and is limiting in terms of the degree of engagement with one another. Musical practice and performance by videoconferencing is an activity where the sense of distance is very much emphasized by the technology, not just by questions of latency (delay), but also, the limits on natural expression that can be reproduced from a fixed perspective. The project involves integrating video rendering of one or more remote performers, with the video acquired from a camera array, into a musician's AR headset display, such that the remote performers appear in the environment as would a physically co-present performer. In other words, distributed musicians should be able to move about, see each other from the correct vantage point, and gesture to one other (e.g., for cueuing in jazz performance), appearing life-like in the display. To do so, we will employ novel pseudo-lightiield rendering approaches of camera array inputs, implemented as a computationally efficient architecture to minimize delay, and "carve out" the remote performer from their background, blending them into our own space within an augmented reality headset. Video rendering will be accompanied by low-latency audio transport so as to permit effective musical telepresence interaction between the performers. Your tasks will include:
- calibrating visible light cameras with time-of-flight cameras for use with third party view synthesis software
- comparison of performance to existing view synthesis technique using only visible light cameras
- verify multi-camera frame synchronization timing for simultaneous acquisition
- refinement of live stream rendering architecture in conjunction with HoloLens2 and Varjo XR3 HMDs
- implement visual hull segmentation of musician from background for blending into AR display
- dynamic view perspective update based on user motion
- output user pose information from HMD to audio subsystem to drive spatial audio display effects
- compare response latency between devices
- integrate foreground occlusion handling
 Enhanced social intelligence in teleconferencing systems
Enhanced social intelligence in teleconferencing systems
The project involves prototyping of a systems architecture to enhance social engagement between distributed (remote) friends or family members participating in a shared media experience, such as watching a sports event or a movie (think Netflix Teleparty) that enhances their sense of connection without distracting from the main activity. The design challenge relates to picking up on emotionally important cues, such as one person becoming excited, scared, or agitated, and representing this information in a manner such that it can be understood without conscious effort, leveraging sensing through wearables, cameras, and other sensors embedded in the environment, and outputs involving graphical, auditory, and haptic feedback. Experiments will be conducted to determine whether the designed mapping strategies promote participants' sense of presence and connection with each other. Although initially intended for social interactions, the technologies being developed are anticipated to have potential applications to more utilitarian videoconferencing scenarios as well.
 Haptic Wearables
Haptic Wearables
Our lab works on the design of wearable haptic devices that can be attached to the body or inserted into regular clothing, capable of sensing human input and delivering richly expressive output to the wearer. We are particularly interested in applications to rehabilitation therapy, sports training, information communication, virtual reality, and mobile gaming. For such purposes, we have built several generations of haptic-augmented footwear, some intended for basic dance training, and others to complement or replace the graphical, auditory, and haptic rendering capabilities of our immersive CAVE environment, providing perceptually engaging experiences of foot-ground interaction during walking on various (simulated) ground surfaces, such as ice, snow, gravel, and sand. While the footwear microelectronics could benefit from more elegant and robust assembly, the primary research challenges we are tackling now are more on the software side:
- Do you often confuse your left foot with right while learning a new dance step? Or lose count of the beats? Or wonder how exactly the trainer is putting their weight onto their feet? Learning a new motor skill typically requires repeated physical practice, cognitive training, and retention. However, it is often difficult for novice dance learners to follow the specifics of rhythm, spatial movement and body posture, while in sync with the instructor, at a defined pace. We are therefore interested in studying the recognition of correct and incorrect dancer movements based on data from the shoes' sensors and the beat of the music, the design of vibrational feedback cues that can be provided to the learner's feet during dance training, and the triggering of these haptic patterns in response to the dancer's foot movement, timing, and pressure, in a manner that best facilitates acquisition of the relevant "basic" dance skills.
- For our ground surface simulations, the haptic effects were initially produced by a CUDA-based physics engine and delivered to the wearer while walking on the tiles of our CAVE floor. We wish to modify these effects as suited to the smaller actuators embedded in the footwear, and demonstrate the potential evocative power of such an architecture by simulating the experience of stepping into a water puddle, combined with a graphical VR display, largely developed, which renders the water ripples in response to foot-water contact.
![]() Ai-Digital Nurse Avatar (ADiNA)
Ai-Digital Nurse Avatar (ADiNA)
Our AI Digital Nurse Avatar (ADiNA) is a GPT-driven graphical
avatar that interacts with users through speech
for medical scenario information gathering and
conversation with older adults for long-term psychosocial assessment
purposes. The primary objective of the initial use case, focused on
interaction with older adults, is to build such AI-based tools to
provide assistance to nurses and other care staff, helping reduce
workload by serving as a possible initial point of communication with
clients, and triaging communications during periods of overload. The
avatars, potentially presenting different on-screen human appearances
and voices, as best-suited to the preferences of each client, collect
information through natural conversation and video-based
interaction. The relevant information would then be conveyed to
appropriate staff in an appropriate format, without necessitating
travel to every client for every interaction. The prototype system
architecture has recently been pilot-tested with nursing staff and
older adults, from which we identified various areas of improvement we
now wish to implement, in addition to other pre-existing needs.
Research tasks include:
- experimentation with GPT-4 and locally run LLMs:
- investigate possibility of improved response times from different LLM options
- investigate performance of locally run LLMs as may be needed in situations where data must remain local for privacy reasons
- acquiring metrics of the user's well-being (psychosocial state), and comparison against baseline models, involving:
- analysis of answers to questions posed by the simulated nurse
- analysis of para-linguistic content such as tone of voice, indicative of affect or mood
- analysis of video of physical movements and facial expression
- conversation flow management
- with nurses: structured model-building of older adult user via formal triage-style interaction, including solicitation of information regarding "any other topics of relevance"
- with older adults: prompting user with possible initial topics of conversation
- customized GPT prompts based on input from nurses as to cognitive/conversational skills of older adult
- visually indicating when ADiNA is "thinking" vs. waiting for user input
- speech handling augmentations:
- multi-lingual text-to-speech (beyond English and French, which are currently supported)
- support for interruption (barge-in) while ADiNA is speaking for improved natural interaction
- detection and discrimination of multiple human speakers, e.g., for group conversations and suppression of background noise
- feature additions:
- expanded access to real-time data sources to support greater range of discussion topics
- integration of image/video input interpretation capabilities for understanding of the user's environment and the user's own activity
- integration of on-demand video synthesis capabilities, leveraging AI video creation tools
We are seeking talented and motivated students to join this project to contribute to one or more of these tasks. Experience with the relevant ML frameworks, speech recognition and synthesis APIs would be a strong asset, although not essential.
 Comparing collaborative interaction architectures
Comparing collaborative interaction architectures
Imagine designing an IKEA kitchen layout with your partner. Would it be easier and more efficient to do so by working with the 20-20 3D viewer IKEA Home Planner on a conventional computer display, or doing so in 3D with AR glasses, directly in your own kitchen environment, or perhaps, working collaboratively in an immersive 3D design environment? That's the question that this project seeks to answer, by comparing performance and user experience through a study that evaluates the benefits of working collaboratively on the design task under different environments.
Whereas the IKEA and Hyve3D design software already exists, to carry out the same task under the HoloLens condition, the student(s) will need to work in Unity, developing the code to share the scene model being developed and manipulated within the environment, so that the evolving kitchen layout can be experienced together by the kitchen layout "co-designers". Comparison and analysis of the effectiveness of task collaboration supported by the different tools will follow a framework inspired in part by a recent study of collaboration in handheld AR environments.
 Touching faces in VR
Touching faces in VR
Most haptics wearables focus on delivery of tactile stimuli to the human body, but rarely consider the face, which is an important area of social touch, especially for couples and parent-children relationships. This project will explore the possibilities for delivering remote touch to the face, and eventually, of feeling a sensation of doing so, in the virtual environment. The architecture will be based on a soft wearable prototype, which operates in conjunction with audio-graphical stimuli in the VR space. We anticipate simulating such interactions as a mother caressing the face of her child, or planting a kiss on the cheek. Applications extend not only to social interaction but further to treatment of medical conditions (e.g., phobia therapy).
The project involves the following deliverables:
- Investigation of design requirements for a haptic wearable to deliver stimuli to the face
- design and implement a prototype employing our soft actuation technology to deliver the appropriate stimuli
- integrate the prototype within a VR environment for the perception of remote touch
- design and carry out a user study and evaluate the results
The project is suitable for highly motivated student(s) from Electrical and Computer Engineering or Mechanical Engineering who seek to gain multidisciplinary experience, in particular, related to haptics and soft robotics. Experience working with one or more of 3D CAD modeling, Unity, microcontroller programming, system control, and design and execution of user studies are highly desirable.
 Inducing temperature illusions through withdrawal reflex
Inducing temperature illusions through withdrawal reflex
We previously demonstrated that a simulated heat withdrawal response through a suitably timed electrical muscle stimulation (EMS) could elicit perception of a warmer temperature. However, potential experimental confounds need to be investigated to determine whether the observed effect is due specifically to muscle activation (i.e., that the artificial withdrawal response was a reaction to heat) or could equally be induced through delivery of other stimuli, such as vibration. To do so, this project will modify the hardware apparatus to deliver different stimuli and then carry out a follow-up research study.
 Content Authoring for 4DX Cinema
Content Authoring for 4DX Cinema
Building on our first-generation prototype, this project aims to develop an open-source interactive authoring tool to control a multimodal haptic armrest to enhance the user experience of viewing audio-visual media. The haptic armrest delivers sensations of vibrotactile, poking, airflow, and thermal (cooling/warming) stimuli. Anticipated contributions include an open-hardware design for the armrest, and a context-aware haptic authoring tool that facilitates the design and manipulation of immersive haptic effects, integrated with audiovisual media (e.g., movies, games, and sport events).
The authoring tool will be developed in a cross-platform language of framework and will provide: 1) an extensible architecture, using XML descriptions of I/O so as to support the addition of novel actuators and configurations, 2) an easy-to-understand graphical user interface, such as those found in popular video editing tools, in which effects appear on a media timeline, 3) computer-assisted haptic authoring support based on analysis of the audiovisual media.
This project is suitable for an Honour's thesis student or capstone team interested in human-computer interaction, multimedia computing, and haptics, ideally with strong software development skills.
Resources: The student(s) will be provided with our prototype haptic armrest hardware, sample code (Arduino) to actuate the various components of the armrest, and the audiovisual analysis algorithms we have tested for automatic generation of vibrotactile effects.
 Measuring Skin-coupling of Wearable Devices
Measuring Skin-coupling of Wearable Devices
How firmly a wearable device, such as a smartwatch, is coupled to the body can change how its haptic effects are perceived and its ability to measure physiological signals. However, researchers and wearable-makers often rely on vague subjective coupling characteristics such as "strapped snugly" or "tight yet comfortable". Achieving consistent strap tightness across body sites and between users can be challenging, since even if strap tension is consistent, differences in limb circumference alter the resulting normal force under the wearable system in potentially unintuitive ways. Furthermore, when users must attach the devices, they may not use the same tightness each day. We have developed a system that aims to assist people in putting wearable devices on their body in a consistent manner.
This project involves the validation of the sensing principles employed, the implementation and evaluation of the approach in a functional wearable prototype, and participation in the submission of an academic paper, which will include literature review, writing, and editing activities.
This project is suitable for a highly motivated and autonomous Honour's student, ideally, familiar with or having interests in physiological signal processing, basic machine learning, design and execution of user studies, and interest in publishing their work in an academic venue.
 Real-Time Emergency Response
Real-Time Emergency Response
Real-Time Emergency Response (rtER) was a winner of the Mozilla Ignite challenge that called on teams to design and build apps for the faster, smarter internet of the future. Specifically, rtER allows emergency responders to collaboratively filter and organize real-time information including live video streams, Twitter feeds, and other social media to help improve situational awareness of decision makers in emergency response scenarios.
A concern related to the use of such a system in real emergency response scenarios is the danger of information overload and the associated demands on limited resources. To mitigate against this concern, we are employing simple video summarization algorithms and techniques that match similar videos into clusters, thereby significantly reducing the amount of content that must be viewed in order to gain an understanding of an emergency situation. These mechanisms will be integrated into the rtER platform.
We would like to incorporate additional capabilities as summarized in the following sub-projects:
- updates to iOS port of mobile client
- integration of audio communication and recording from mobile client streams
- migrating our existing HLS-based streaming architecture to the newer Dynamic Adaptive Streaming over HTTP (DASH) standard
- implementing a security layer involving user accounts, access control, secure identification of video streams, and HTTPS encryption
- enhancing the existing visualization architecture to better integrate live video and embed emergency-related information display
- investigating feature-matching for dynamic video mosaicing from moving or multiple video streams
- developing the infrastructure to support crowdsourced video analytics
- implementing chronology-based "event timelines" that allow viewers to scroll back to previous states during review of an emergency or crisis event
Project Team: 1-4 members
Skills: strong software development ability, plus specific skills as relevant to the individual sub-project(s)
 360° camera scene understanding for the visually impaired
360° camera scene understanding for the visually impaired
Despite the popular misconception that deep learning has solved the scene recognition problem, the quality of machine-generated captions for real-world scenes tends to be quite poor. In the context of live captioning for visually impaired users, this problem is exacerbated by the limited field of view of conventional smartphone cameras and camera-equipped eyewear. This results in a narrow view of the world that often misses important details relevant to gaining an understanding of their environment.
This project will make use of a head-mounted 360° camera and a combination of human (crowdsourced) labeling with deep learning to train systems to provide more relevant and accurate scene descriptions, in particular for navigation in indoor environments, and guidance for intersection crossing, improving upon a system recently developed by our lab for this purpose. Results will be compared to those obtained using camera input from a smartphone held in a neck-worn lanyard.
Past Projects
Electrical and Computer
 Chatting with the (historical figure) stars
Chatting with the (historical figure) stars
This project will develop a prototype platform to enable near-real-time conversations with your favourite historical personalities, using a combination of AI tools for avatar rendering and dialog management. The pipeline will consist of:
- obtain input questions from the user who wishes to speak with a historical figure
- use a generative AI platform such as DALL-E to create an image of the historical figure, possibly in a specified context (e.g., Nietzsche in a pub)
- provide the input query to a language model such as ChatGPT to obtain text output from the chosen figure
- animate the image of the generated character as a cartoon or possibly photorealistic avatar
- have the avatar speak the output text through a speech synthesis framework, matching specified vocal characteristics, potentially following the approach used here
Haptically Enabled Learning of Phonemes (HELP) for Reinforced Language Acquisition
This project relates to improving one's skills in a second language by employing a novel vibrotactile phoneme encoding mechanism to facilitate language learning and pronunciation. This can be used both as an augmentation to the audible properties of a second language, and as a feedback mechanism during speech practice.
Although the time required to render phonemes through our prototype mechanism is too slow for speech rates, it is acceptable for individual word training, since the learner is likely to spend at least a few seconds working on the pronunciation of a new word. This project will investigate optimal designs for faster haptic rendering, which is feasible since the learning task in this scenario only requires that the encoded phonemes be discriminated from one another, rather than necessary "understood" as speech. The vibrotactile phoneme encoding can be used more sparsely during speaking practice by rendering its output only in the case of a mispronunciation by the learner. In this manner, it would signal both the mispronunciation event itself and provide feedback as to the correct pronunciation.
Project tasks will involve a combination of haptic rendering design, speech signal processing, interaction design, and carrying out user experiments to compare designs.
 Mixed reality audio rendering for improved information communications
Mixed reality audio rendering for improved information communications
This project involves the exploration of novel strategies for auditory rendering in a mixed reality scenario such that the computer-generated information is delivered to the user in a more effective manner, facilitating awareness of such information while minimizing interference with the user's attention to other activities. The student should be familiar with the basics of signal processing techniques, and be comfortable rapidly prototyping different design concepts. Mobile development experience would be particularly useful.
 Mixed-Reality Platform for Simulation and Synthesis of Multi-Modal Hallucinations with Applications to Schizophrenia Treatment
Mixed-Reality Platform for Simulation and Synthesis of Multi-Modal Hallucinations with Applications to Schizophrenia Treatment
Treating patients with schizophrenia for auditory hallucinations has traditionally required multiple trials of antipsychotic medications, to which approximately one in three patients are resistant. An alternative, Avatar Therapy, has been shown to effectively reduce the distress and helplessness associated with auditory hallucinations. While Avatar Therapy holds great promise, there are many open questions as to the requirements for optimal delivery of this treatment. Similarly, many potential enhancements to how avatars are rendered to the patient remain to be tested. Exploration of these questions and enhancements requires development of a mixed reality platform that offers to the therapist the ability to easily adjust various parameters of the avatar(s). We will iteratively design, implement, and test such a platform, and then apply the knowledge gained to an augmented reality version of the platform suitable for use outside of the therapist's office. The resulting intelligent medical device will offer the possibility of providing therapeutic benefits to patients in their day-to-day activities.
This project involves the following components:
- Graphical and audio avatar rendering: developing a Unity- and 3D-audio-based avatar manipulation system for display in a VR or AR headset
- Speech pipeline, involving recognition of tell-tale vocal indications of a hallucination episode, and speech rendering in the voice of the avatar, initially from the therapist's input, but later, generated semi-automatically
- Haptic augmentation: prototyping and testing wearable technologies suitable of reproducing the sensation of someone touching or grabbing your arm or shoulder
- Biosignals-based quantitative evaluation: making use of ocular biomarkers and other physiological indicators of stress to measure affective state
 Exploration of style mixing on StyleGAN2 to design new paradigms of interaction for avatar-creator interfaces
Exploration of style mixing on StyleGAN2 to design new paradigms of interaction for avatar-creator interfaces
This project focuses on the graphical synthesis of avatars that can be customized by patients and therapists, for the Avatar Therapy project, described above. The interface for avatar creation must provide users with a great variety of customization options to closely match patients' mental representation of the hallucinations while keeping interactions as simple as possible.
These constraints motivated the development of a machine learning approach based on Generative Adversarial Networks (GANs), which are state-of-the-art networks to generate high-quality and high-resolution faces. The main challenge of this approach is to design new interaction paradigms to enable a non-engineer user to control the output of the network and converge towards a face that makes patients feel they are in the presence of their hallucination.
We generate faces using the open source StyleGAN2 network. This is trained using style mixing regularization, which is a regularization technique based on style transfer. It enables the network to specialize layers into synthesizing different levels of details in the output face. This particular training method can be leveraged to perform style mixing, generating a new output that combines coarse aspects of one face with finer aspects of a second one, as illustrated in the image above.
Project objectives, in chronological order, are as follows:
- gain familiarity with the framework, in particular, the style mixing scripts, and reproduce the results of Karras et al.'s StyleGAN2 paper
- generate different design ideas for a UI based on style mixing for avatar creation
- implement the most promising design preferably under the format of a web application
- proceed with user testing to determine the validity of the style mixing approach. Analyze the results to point out strengths and weaknesses
- draw conclusions on how this approach could be combined to other approaches currently developed at the SRL
- integrate the style mixing approach into the existing system based on other approaches
Project Team: 1-4 members
Skills: Students should be reasonably well versed in machine and deep learning, with interests in human-computer interaction and web applications and have relatively strong programming skills in Python and web development (HTML, JavaScript). Familiarity with Git would be particularly useful.
 Haptic device for sensory reeducation applications
Haptic device for sensory reeducation applications
Nerve damage, frequently caused by injury, can result in the loss of sensorimotor functions in certain parts of the hand. After suturing the nerve, unpleasant sensations on contact, including tingling and electric shocks are often felt. Following nerve regrowth, it is necessary to re-train the brain to interpret the signals from these nerves correctly.
This project involves the design of haptic devices to help in the process of sensory reeducation, which can involve two phases, depending on the severity of the loss of sensitivity: relearning how to localize sensations, and differentiation of shapes and textures in the identification of objects. Reeducation and stimulation should be started in a timely manner post-injury for maximum neuroplasticity benefits. However, since areas of injury often cannot be touched right away due to sterility concerns, we require some means of contactless skin stimulation, which is now feasible with the use of ultrasonic haptics and the associated Leap motion hand-tracking system.
Unity experience is strongly desirable, since this environment will be used to interface to the controlling and sensing hardware.
.png) AR and 360: toward the camera-mediated future
AR and 360: toward the camera-mediated future
Augmented reality glasses are gaining popularity, with several products in the market, including Microsoft Hololens 2, the Vuzix Blade, the Everysight Raptor, Magic Leap and Google's Enterprise Edition 2. However, most applications remain limited to basic information display overlays, or mixed reality games, which, while no doubt compelling, are relevant only for isolated use in specific contexts. As the technologies improve, leading to lighter, more comfortable, and power-efficient devices that can be worn all day, we are interested in exploring the potential for head-worn displays and imaging devices to enhance our capabilities as a fixture of everyday activity, just as smartphones augment our communication and memory. At the same time, it is important that we gain a better understanding of how people wearing such devices will interact with and be perceived by others, if they are to gain social acceptability--a lesson not lost on Google.
This project will: 1) prototype several applications related to navigation in the everyday world with a particular emphasis on the use of 360° video input as a potentially valuable information source, e.g., providing visual guidance to someone who needs to retrace their steps to return to their car, and 2) examine social reactions and acceptability of different form factors and visible (to the outside) clues of head-worn camera operation.
 Multimodal monitoring for high-consequence environments
Multimodal monitoring for high-consequence environments
We are exploring the delivery of monitoring information from complex systems, for example, patient vital signs or industrial plants, to those responsible for monitoring the system, e.g., clinicians in the OR and ICU, or plant operators. The challenge is to do so in a manner that allows the clinician or operator to maintain state awareness and easily notice problems that warrant intervention, but without imposing significant demands on their attention or cognitive resources. To this end, we have developed a novel, efficient, approach to delivering such information using haptic actuators, in which the transitions from a "normal" to "abnormal" state are readily apparent and easily identifiable. This project will expand on the current rendering technique and investigate the tradeoffs between haptic and auditory representations in terms of their effectiveness in supporting situational awareness and decision-making. Students should be creative experimentalists, quick learners, and have a reasonable understanding of signal processing techniques.
 Enhanced Remote Viewing Capabilities from a Camera Array
Enhanced Remote Viewing Capabilities from a Camera Array
Our camera array architecture, initially developed for remote viewing of surgical (medical) procedures, provides real-time viewpoint interpolation capabilities, allowing users to look around the scene as if physically present. We are now interested in applying this architecture to more general video-mediated activities, including face-to-face videoconferencing, and exploring the potential to leverage mobile interaction with the array in a manner that compensates for the limited screen real estate of mobile devices.
This project will examine the qualitative experience of telepresence when using a smartphone display as a mobile window into the remote environment by updating the software as required to run on the newer architecture of hardware available, and preparing and conducting an experiment comparing the mobile telepresence capabilities with a pan-tilt-zoom camera, and a fixed large-screen display. Specific tasks include: 1. Updating the software architecture of the (Ethernet-based) camera frame acquisition and interpolation routines, and the transmission of the rendered video to smartphone, to run on our current generation of hardware and available support libraries. 2. Acquisition of test video footage from multiple calibrated video sources. 3. Configuring and testing the existing software architecture to make use of pre-recorded video sources, which may involve direct retrieval of uncompressed data from RAM or possibly real-time decoding of compressed video from SSD. 4. Recording of the actual experimental video content, which will involve some human activity that must be "judged" by the experiment participants. 5. Implementing the virtual pan-tilt-zoom camera to support one of the experiment conditions. 6. Carrying out the user study and evaluating the results.
Project Team: 1-2 members
Skills: systems experience, good programming knowledge, interest in human-computer interaction and experimental studies
 Augmented Reality Tools for Enhanced Training of First Responders
Augmented Reality Tools for Enhanced Training of First Responders
This project is intended to equip firefighters with a heads-up-display (similar to Google glass) that provides them with valuable information related to their task, e.g., pointers to the nearest exit point and a breadcrumb trail indicating the path taken to the present location. The system was developed initially with support from the Mozilla Gigabit Community Fund and trialled with firefighters in a simple training scenario. Recent updates have integrated indoor positioning information, along with other sensor data from the TI Sensor Tag. Now, these data must be integrated to render the appropriate view of virtual content, overlaid correctly with the real-world scene. Sub-projects include:
- Building 3D indoor maps using the Project Tango tablet and leveraging this information for improved accuracy of indoor position and visualization of environment in low-visibility conditions.
- Incorporating position and orientation knowledge to render the relevant virtual information, including maps, waypoints, beacons, exit markers, and locations of other responders, as a see-through augmented reality display.
- Integrating new interactivity, allowing the firefighters to share information through the system, correlate their position with a map display, mark locations within the environment, and access additional data from external sensors such as the TI SensorTag.
Project Team: 1-3 members
Skills: strong software development ability, in particular on Android platform (for our augmented reality display); computer graphics experience would be highly desirable
 Mobile Mixed-Methods Data Collection for Machine Learning Applications
Mobile Mixed-Methods Data Collection for Machine Learning Applications
Numerous artificial intelligence projects aim at recognizing high-level psychological concepts such as emotions or anxiety. There is significant interest in doing so in the mobile case, that is, using smartphones or wearable devices. However, these projects are hindered by a lack of large labeled datasets, representative of users' different contexts, e.g., activities, day of the week, and weather. Although existing mobile experience sampling methods allow the collection of self-reports from users in their natural environment, they require disruptive notifications that interrupt the users' regular activity. We have conceptualized a new data collection technique that overcomes this problem, allowing for the collection of large amounts of self-reporting data without such interruption.
Starting from an existing prototype implementation of this data collection technique, this project aims to extend the self-reported data with quantitative data collection capabilities, i.e., smartphone sensor data and physiological signals. The objective of these modifications is to enable use of this data collection framework in practical machine learning applications. The outcomes of this project have the potential to contribute significantly to the fields of applied machine learning, user-centered artificial intelligence and affective computing.
Multimodal alarms for the OR and ICU
At present, the operating room (OR) and intensive care unit (ICU) are noisy environments, exacerbated by frequent alarms. Regardless of whether the alarms are valid or false, all command attention, raise stress, and are often irrelevant to the responsibilities of individual clinicians. To cope with these problems, this project investigates the possibility of using multimodal alarms, preserving audio for those alarms that should be announced to the entire team, but delivering certain alarm cues individually, through haptics (vibrations) to the feet.
As a first step, the project will involve designing and conducting an experiment to determine the degree to which both haptic and audio alarms can be learned, recognized in the context of other demanding activities, and to quantify the reaction times and accuracy to such cues, comparing unisensory auditory and multisensory auditory and haptic stimuli. We will employ the stop-signal reaction task (SSRT) and Profile of Mood States (POMS) during pre and post paradigm exposure to quantify the fluidity of attentional decision-making and fatigue, respectively, to the unisensory and multisensory conditions.
Through these experiments, we hope to determine preliminary guidelines for the number of distinct alarms that can be conveyed effectively through haptics, leading to a reduction in the demands on the audio channel. (This project is being conducted in collaboration with a US-based professor of Anesthesiology Critical Care Medicine.)
 Mixed reality human-robot interaction for reduction of workplace injury
Mixed reality human-robot interaction for reduction of workplace injury
As part of a multi-site FRQNT-funded project, we are investigating the use of mixed reality in a human-robot interaction scenario to reduce the risk to workers arising from musculo-skeletal injury. The concept is to provide workers with an interface that adequately conveys the visual, auditory, and haptic cues to permit efficient manipulation and control of their tools, but in a safe manner.
Our recent efforts resulted in the development of a lightweight replica of the tool handle, equipped with sensors and actuators, that allow the user to manipulated a mixed-reality model of the actual tool. Graphical augmentation, using a CAD model of the tool, and optionally, video overlay through a see-through display, will give the operator a visual impression of how the tool is responding, while recorded or synthesized sound, measured forces, torques, and vibrations, acquired by sensors at the tool end, will be mapped to auditory and haptic feedback cues delivered at safe levels to the operator, facilitating effective operation while avoiding RSI.
At present, manipulation of the handle is tracked with an optical motion capture system, and the mixed reality display is rendered through an Epson Moverio BT-200 display, but we are seeking to migrate to an Acer mixed-reality device, providing full-screen immersion and built-in motion tracking.
The project includes the following sub-tasks:
- instrumentation of actual tool with sensors for acquisition of force, torque, and vibration data
- reproduction of acquired sensor data at replica tool handle, complemented by task-specific graphical display
- improved rendering of tool state information, including graphical, auditory, and vibrotactile modalities, in the user's workspace
- integration of the 3D-printed tool handle with a force-feedback haptic device to enrich the perceptual experience of (tele-)manipulation of the actual tool; this will eventually be replaced by an actual cable-driven robotic assembly being developed by colleagues at Université Laval
Untethered Force feedback for virtual and augmented reality interactions
We regularly experience force and vibrotactile feedback from our everyday interactions with physical objects. For virtual and augmented reality scenarios, a wide range of vibration effects can be generated using vibrotactile actuators. However, reproducing the effects of force has typically relied upon robotic systems such as the Senseable Phantom, which must be supported (grounded) to provide their feedback, and are therefore not suitable for use outside of a limited workspace. To provide the experience (or illusion) of force feedback in mobile applications, such as for hand-held game controllers, researchers have experimented with the use of solenoids, flywheels, and electrical muscle stimulation. In this project, we will make use of such mechanisms and investigate related approaches to convey force feedback to users of both hand-held and wearable devices, in particular, to simulate the effects of object collision. An initial application is to improve the haptic experience of working with a simulated power tool in a VR environment.
 Vision-based intersection-crossing assistance for the visually impaired
Vision-based intersection-crossing assistance for the visually impaired
Our lab has developed a vision-based machine learning (neural network) prototype that provides auditory feedback to visually impaired users to help them keep within the designated safe crossing zones at pedestrian intersections. Users wear a smartphone on a lanyard around their neck, and activate the feedback when they are ready to cross. However, to make the prototype useful in practice, additional training data should be collected and labeled, and several design issues need to be addressed:
- The lanyard naturally sways from side to side due to the user's motion. Therefore, image capture must be sensitive to the gait cycle timing so as to avoid biasing the feedback as a result of this sway. Ideally, this can be done by acquisition of images at the mid-point of the swing, as determined by reading the IMU, or otherwise, by training the system to compensate for the angle of the smartphone.
- When the neural network is uncertain of the user's orientation relative to the intersection crossing, possibly because of significant occlusion of the view, we would like to make use of IMU data to estimate the change in orientation since the last output from the vision-based process. In this manner, the system can continue providing useful feedback, rather than having to report a failure condition, or remaining silent.
- Since the system is intended to be integrated as a component of our Autour app, the crossing assistance feedback could be activated automatically every time the user approaches an intersection. If such an "auto-start" feature is enabled, it will be necessary to carry out additional training of an intersection-detection network, possibly combined with GPS data, to determine proximity to known intersections.
 Development of a new haptic interface for the feet
Development of a new haptic interface for the feet
Haptic perception through the feet informs a wide range of dynamic and static human activity. Stimulating the foot, for example to render virtual ground surface reactions, requires comparatively strong, and thus large actuators due to their placement between the ground and a human loading the foot. In stationary setups, actuators can be integrated into static assemblies at the ground surface. However, this is not feasible for mobile applications, for which the stimuli must be provided wherever the user happens to be. In such scenarios, delivery of sufficiently strong stimuli through conventional haptic actuators, such as voice coils, poses a significant challenge in terms of the associated electrical power requirements. Our project will implement new approaches to help render the stimuli with sufficient force, thereby overcoming this challenge.
Specifically, we would like to implement a variant of a design suggested by Berrezag, Visell and Hayward for an amorphous haptic interface for reproducing effects of compressibility and crushability (Berrezag et al., EuroHaptics 2012). Their design is based on two deformable chambers, made of oriented polymers, such as biaxially oriented polypropylene (BOPP), and connected by a conduit filled with magnetorheological (Mr) fluid. By varying the viscosity of the fluid through changes to the applied magnetic field, the system can be used to render various haptic effects, stimulating different textures and material behavior. Our proposed variant offers certain advantages, and has potential applications to rehabilitation, gaming, and VR.
 Non-Intrusive Mobile Experience Sampling Methods for Machine Learning Applications
Non-Intrusive Mobile Experience Sampling Methods for Machine Learning Applications
Numerous artificial intelligence projects aim at recognizing high-level psychological concepts such as emotions or anxiety. There is significant interest in doing so in the mobile case, that is, using smartphones or wearable devices. However, these projects are hindered by a lack of large labeled datasets, representative of users' different contexts, e.g., activities, day of the week, and weather. Although existing mobile experience sampling methods (ESM) allow the collection of self-reports from users in their natural environment, they require disruptive notifications that interrupt the users' regular activity.
We have conceptualized a new data collection technique that overcomes this problem, allowing for collection of large amounts of self-reporting data without such interruption. This project aims to explore several designs for the technique, implement the more promising ones, and test them. The result has the potential to contribute significantly to the fields of applied machine learning, user-centered artificial intelligence, and affective computing.
Tasks include:
- Interaction design: Apply user-centered design techniques to the creation of mobile graphical user interface (GUI) layouts that would allow the reporting of different types of data, e.g., current anxiety level on a continuous or Likert scale.
- Mobile implementation: Android and/or iOS implementation of the preferred interaction designs.
- Validation: Design and execution of a user study quantifying the improved performance and user experience of the new reporting system in comparison with existing experience sampling methods. This will form part of a conference or journal paper submission.
 Wine Recommender
Wine Recommender
Within the context of an industrial collaboration, we are undertaking the design and prototype development of a recommendation system for wines that begins with limited user data, and over time, becomes tailored to the individual consumer's tastes and profiles of similar users. The objective is not only to offer recommendations that the user is likely to enjoy, but also to help educate users as to specific characteristics of the wines. Much of this project can be viewed as a conventional machine learning challenge, but there is an arguably even more important component that relates to the user experience. Thus, significant effort will be allocated to gaining an understanding of how the target audience for the app currently makes their wine selections, and ensuring that the app supports existing habits.
Sub-projects include:
- User modeling: Develop tools to fit individual users into general groupings related to their interest and knowledge of wines, and wine preferences initially known, with minimal interaction requirements, e.g., a lightweight app enrollment process.
- Interaction design: Develop and test several interface iterations that offer wine recommendations based on the user's profile and current interests, in a manner that includes an explanation of the characteristics of the wine that make up part of the logic for particular recommendations.
- Exploratory recommendation engine: Develop a content-based filtering algorithm with a tunable exploration bias, that generates recommendations based on a user profile and input related to the user's immediate interests.
 Social Media Analytics
Social Media Analytics
We developed tools for scraping social media feeds for posts of relevance to public safety, to facilitate early detection of events including flooding, highway accidents, road closures, fires, and downed electrical lines. The system was installed for the use of the Ministère de la securité publique of Quebec.
 Video tagger and classifier UI
Video tagger and classifier UI
We developed the infrastructure for a web-based video tagging interface and a prototype object-and-event detector. Together, these tools could allow for both manual and automated tagging of video clips in popular repositories such as YouTube and Vimeo. We now wish to build on this architecture by improving the toolkit of object and event detection capabilities that can be tailored for a variety of general-purpose video analytics purposes. Our long-term objective is to combine these tools with user feedback on the automated detection to train more complex recognizers using machine learning techniques.
 Open Orchestra
Open Orchestra
The orchestral training of professional and semi-professional musicians
and vocalists requires expensive resources that are not always available
when and where they are needed even if the funding for them were made
available. What is needed is the musical equivalent of an aircraft
simulator that gives the musician or vocalist the very realistic
experience of playing or singing with an orchestra. The purpose of
making this experience available through a next generation
network-enabled platform is to provide the extensive tools and resources
necessary at very low cost and wherever there is access to a high speed
network.
 Health Services Virtual Organization
Health Services Virtual Organization
The HSVO aims to create a sustainable research platform for experimental development of shared ICT-based health services. This includes support for patient treatment planning as well as team and individual preparedness in the operating room, emergency room, general practice clinics, and patients' bedsides. In the context of the Network-Enabled Platforms program, the project seeks to offer such support to distributed communities of learners and health-care practitioners. Achieving these goals entails the development of tools for simultaneous access to the following training and collaboration resources: remote viewing of surgical procedures (or cadaveric dissections), virtual patient simulation involving medical mannequins and software simulators, access to 3D anatomical visualization resources, and integration of these services with the SAVOIR middleware along with the Argia network resource management software.
 Simulating a Food Analysis Instrument
Simulating a Food Analysis Instrument
We build on HTML5 and other web-related technologies to implement a simulator used for teaching the use of a spectrometer for the detection of food bacteria (e.g., in yogurt, milk, or chicken). Accurate detection of these bacteria is an important topic in the food industry, which directly impacts on our health and wellbeing. Importantly, making such simulators available through the web allows access to the underlying pedagogical content and training of students in third-world countries, where the Internet is available, but qualified educators are in short supply. Hands-on experience with a simulator of sufficient fidelity, especially one designed with instructional case scenarios, can provide invaluable educational and training opportunities for these students that would not otherwise be possible. In our simulator, the student is presented with a case scenario of food poisoning in a Montreal restaurant, and is then given the task of analyzing a food sample. Various options are presented, ranging from watching a brief documentary of the operation of the machine, to a guided set of steps that the student is invited to perform in a laboratory to solve the task. Users can directly control the knobs and buttons of the simulated spectrometer and are provided with a rich visual experience of the consequences of their actions, as the appropriate video clip is played back (forward or in reverse, e.g., to illustrate the effects of a switch being turned off).
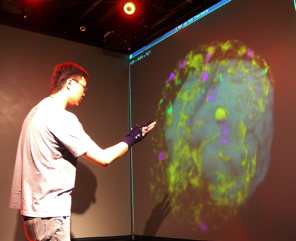 3D Visualization and Gestural Interaction with Multimodal Neurological Data
3D Visualization and Gestural Interaction with Multimodal Neurological Data
This project deals with the challenges of medical image visualization,
in particular within the domain of neurosurgery. We wish to provide
an effective means of visualizing and interacting with data of the
patient's brain, in a manner that is natural to surgeons, for
training, planning, and surgical tasks. This entails three
fundamental objectives: advanced scientific visualization, robust
recognition of an easily learned and usable set of input gestures for
navigation and control, and real-time communication of the data
between multiple participants to permit effective understanding and
interpretation of the contents. The required expertise to accomplish
these tasks spans the areas of neurosurgery, human-computer
interaction, image processing, visualization, network communications.
 Mobile Game Device for Amblyopia Treatment
Mobile Game Device for Amblyopia Treatment
Amblyopia is a visual disorder affecting a significant proportion of
the population. We are developing a prototype device for assessment
and treatment of this symptom, based on a modified game application
running on a compact autostereoscopic display platform. By sending a
calibrated "balanced-point" representation to both eyes, we aim for a
therapeutic process to gradually engage signals from the weaker eye to
engage it in the visual process. The adaptation of this approach from a
lab-based and controlled environment to a portable device for daily
use has the potential to make amblyopia treatment more accessible.
 Enhanced Virtual Presence and Performance
Enhanced Virtual Presence and Performance
This project will enhance the next generation of virtual presence and
live performance technologies in a manner that supports the
task-specific demands of communication, interaction, and
production. The goals are to: improve the functionality, usability,
and richness of the experience; support use by multiple people,
possibly at multiple locations, engaged in work, artistic performance,
or social activities; and avoid inducing greater fatigue than the
alternative (non-mediated) experience. This work builds on recent
activities in Shared Spaces and the World
Opera Project.
 World Opera
World Opera
Can opera be performed if the opera singers are standing on different
stages in different time zones in different countries? This question
is at the heart of the World Opera
Project, a planned joint, real-time live opera performance to take
place simultaneously in several Canadian, U.S. and European
cities. The project is envisioned as a worldwide opera house located
in cyberspace.
 Underwater High Definition Video Camera Platform
Underwater High Definition Video Camera Platform
The Undersea Window transmits live full broadcast
high definition video from a camera on the undersea VENUS
network, 100 m below the surface of the Saanich Inlet on Vancouver
Island, to scientists, educators and the public throughout Canada
and around the world via CA*net 4 and inter-connected broadband
networks. The project will serve as a test bed for subsequent high
definition video camera deployment on the NEPTUNE network in the
Pacific Ocean. We subsequently worked on the development of Web services software that
matches a common set of underwater video camera control inputs and
video stream outputs to the bandwidth available to a particular
scientist and allows scientists to collaborate through sharing the
same underwater view in real time. We then produced a web-based
video camera user interface that makes use of the controls and
features available through these web services. In addition, we
tested an existing automated event detection algorithm for possible
integration into the "live" system.
 Adaptive streaming for Interactive Mobile Audio
Adaptive streaming for Interactive Mobile Audio
This work involves evaluation of audio codec quality in the context of
end-to-end network transmission systems, development of adaptive
streaming protocols for wireless audio with low latency and high
fidelity characteristics, and testing of these protocols in real-world
settings. Our freely downloadable streaming engine,
nStream
is available for Linux, OS X, and Gumstix platforms.
 Augmented Reality Board Games
Augmented Reality Board Games
As novel gaming interfaces increase in popularity, we are
investigating the possibilities afforded by augmenting traditional
game play with interactive digital technology. The intent is to
overcome the physical limitations of game play to create new, more
compelling experiences, while retaining the physicality, social
aspects, and engagement of board games.
 Natural Interactive Walking (aka Haptic Snow)
Natural Interactive Walking (aka Haptic Snow)
This project is based on the synthesis of ground textures to create
the sensation of walking on different surfaces (e.g. on snow, sand,
and through water). Research issues involve sensing and actuation
methods, including both sound and haptic synthesis models, as well as
the physical architecture of the floor itself.
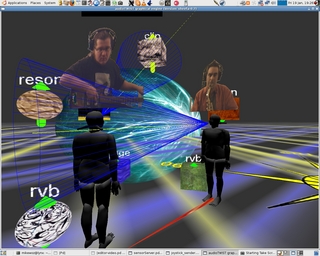 Audioscape: Mobile Immersive Interaction with Sound and Music
Audioscape: Mobile Immersive Interaction with Sound and Music
This project involves the creation of a compelling experience of
immersive 3D audio for each individual in a group of users, located in
a common physical space of arbitrary scale. The architecture builds
upon our earlier immersive real-time audiovisual framework: a modeled
audio performance space consisting of sounds and computational sound
objects, represented in space as graphical objects. Current and
planned activities include experimentation with different technologies
for low-latency wireless audio communication, a large-scale augmented
reality environment to support immersive interaction, and embedding of
3D video textures (e.g., other human participants) into the displayed
space.
 User interface paradigms for manipulation of and interaction with a 3D
audiovisual environment
User interface paradigms for manipulation of and interaction with a 3D
audiovisual environment
We would like to develop an effective interface for object
instantiation, position, view, and other parameter control, which
moves beyond the limited (and often bewilderingly complex) keyboard
and mouse devices, in particular within the context of
performance. The problem can be divided into a number of actions (or
gestures that the user needs to perform), the choice of sensor (to
acquire these input gestures), and appropriate feedback (to indicate
to the user what has been recognized and/or
performed).
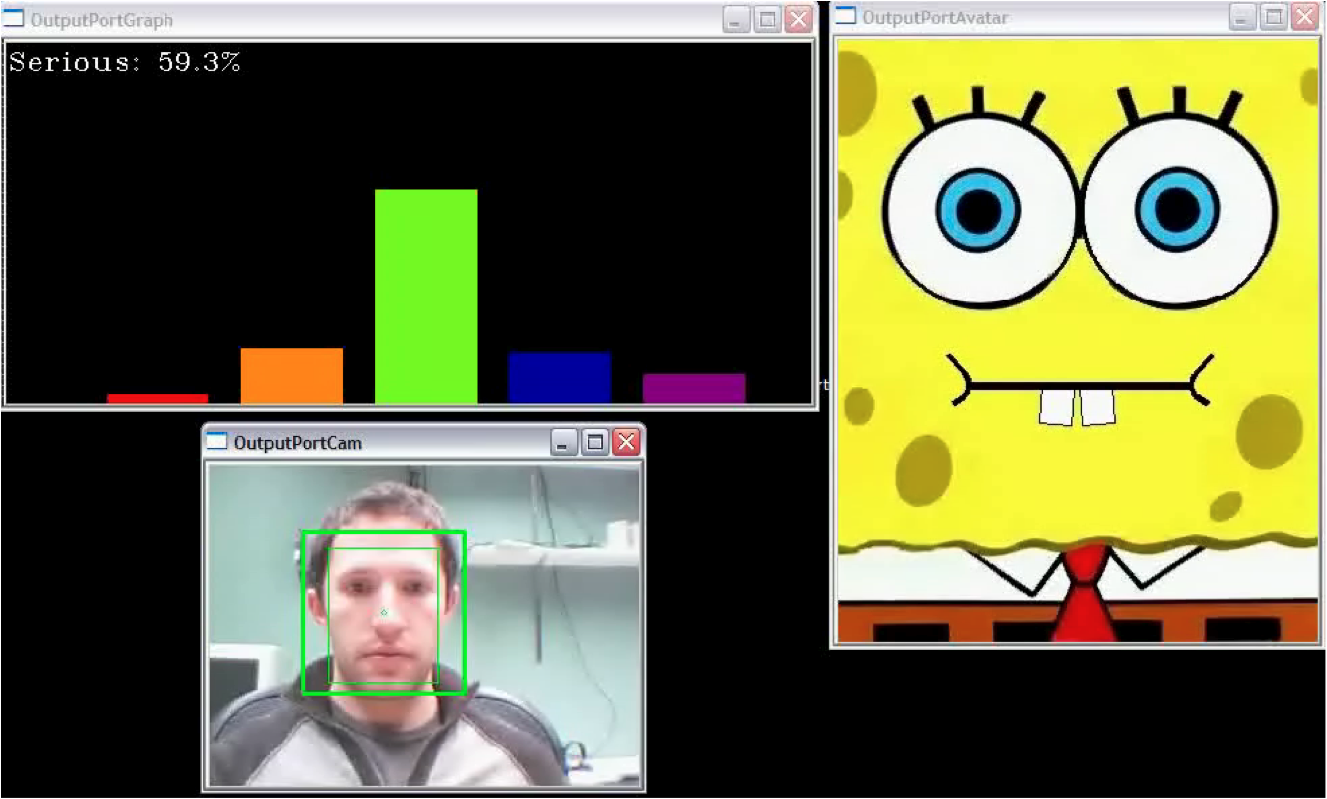 Evaluation of Affective User Experience
Evaluation of Affective User Experience
The goal of this project is to develop and validate a suite of
reliable, valid, and robust quantitative and quqlitative, objective
and subjective evaluation methods for computer game-, new media-, and
animation environments that address the unique challenges of these
technologies. Our work in these area at McGill spans biological and
neurological processes involved in human psychological and
physiological states, pattern recognition of biosignals for automatic
psychophysiological state recognition, biologically inspired computer
vision for automatic facial expression recognition, physiological
responses to music, and stress/anxiety measurement using physiological
data.
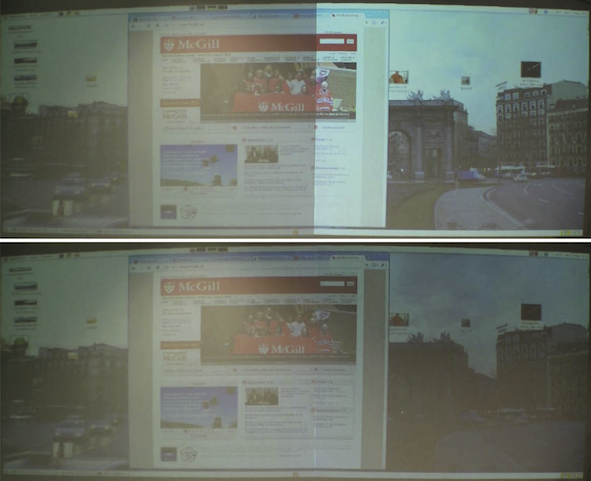 Automatic multi-projector calibration
Automatic multi-projector calibration
Multiple video projectors can be used to provide a seamless, undistorted image or video over one or more display surfaces. Correct rendering requires calibration of the projectors with respect to these surface(s) and an efficient mechanism to distribute and warp the frame buffer data to the projectors. Typically, the calibration process involves some degree of manual intervention or embedding of optical sensors in the display surface itself, neither of which is practical for general deployment by non-technical users. We show that an effective result can in fact be achieved without such intervention or hardware augmentation, allowing for a fully automatic multi-projector calibration that requires nothing more than a low-cost uncalibrated camera and the placement of paper markers to delimit the boundaries of the desired display region. Both geometric and intensity calibration are performed by projection of graycoded binary patterns, observed by the camera. Finally, the frame buffer contents for display are distributed in real time by a remote desktop transport to multiple rendering machines, connected to the various projectors.
 Virtual Rear Projection
Virtual Rear Projection
We transform the walls of a room into a single logical display using
front-projection of graphics and video. The output of multiple
projectors is pre-warped to correct misalignment and the intensity
reduced in regions where these overlap to create a uniformly illuminated
display. Occlusions are detected and compensated for in real-time,
utilizing overlapping projectors to fill in the occluded region, thereby
producing an apparently shadow-free display. Ongoing work is
aimed at similar capabilities without any calibration steps as well as
using deliberately projected graphics content on the occluding
object to augment interaction with the environment.
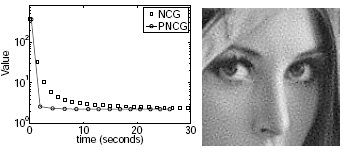 Efficient Super-Resolution Algorithms
Efficient Super-Resolution Algorithms
Super-resolution attempts to recover a high-resolution image or video
sequence from a set of degraded and aliased low-resolution ones. We
are working on efficient preconditioning methods that accelerate
super-resolution algorithms without reducing the quality of the
results achieved. These methods apply equally to image restoration
problems and compressed video sequences, and have been demonstrated to
work effectively for rational magnification factors.
 Dynamic Image Mosaicing with Robustness to Parallax
Dynamic Image Mosaicing with Robustness to Parallax
Image mosaicing is commonly used to generate wide field-of-view results
by stitching together many images or video frames. Existing methods
are constrained by camera motion model and the amount of overlap required
between adjoining images. For example, they cope poorly with parallax
introduced by general camera motion, translation in non-planar scenes,
or cases with limited overlap between adjacent camera views. Our research
aims to resolve these limitations effectively to support real-time video
mosaicing at high-resolution.
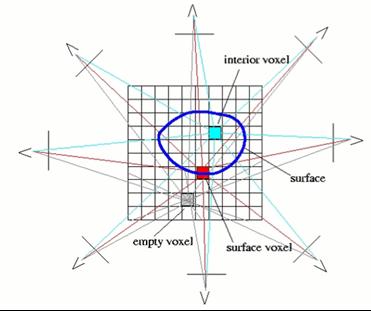 Dynamic View Synthesis
Dynamic View Synthesis
Acquiring video of users in a CAVE-like environment and regenerating it
at a remote location poses two problems: segmentation, the extraction of
objects of interest, i.e., people, from the background, and arbitrary view
generation or view synthesis, to render the video from an appropriate
virtual camera. As our background is dynamic and complex, naive
segmentation techniques such as blue screening are inappropriate. However,
we can exploit available geometric information, registering all background
pixels with the environment empty and then, during operation, determine
whether each pixel corresponds to the background through color consistency
tests. Our view synthesis approach is to build a volumetric model through
an efficient layered approach, in which input images are warped into a
sequence of planes in the virtual camera space. For each pixel in each
plane, we determine its occupancy and color through color consistency,
using this to compose the novel image in a back-to-front manner.
 Machine Learning Techniques for Closed-Loop Gestural Interaction
Machine Learning Techniques for Closed-Loop Gestural Interaction
This project seeks to model the dynamics of movement for the purpose of sensory motor interaction design. The goal is to learn continuous models of movement or gesture, capturing the most salient features of the dynamics as well as the normative ranges of variability, and to do so in a way that facilitates using the movement models in closed loop interaction. The idea is to facilitate the acquisition and use of internal models of the dynamics in question on the part of users.
Two main approaches are being explored: The learning of movement primitives by a kind of parametric semi-Bayesian nonlinear dynamical system (based on the Dynamic Movement Primitives of Ijspeert, Schaal, and Nakanishi), and the modeling of movement by nonparametric Bayesian dynamical systems. The novel aspect is the tight integration of statistical models with nonvisual feedback designed to aid interaction.
 High-Resolution Video Synthesis from Mixed-Resolution Video
High-Resolution Video Synthesis from Mixed-Resolution Video
To increase the frame rate at high resolution of CMOS image sensors,
we propose using their non destructive read-out capabilities to
simultaneously generate high-resolution frames H at frame
rate h and low-resolution frames L at frame rate l
> h. Our method applies an image-processing algorithm to
both sequences in order to synthesize a high-resolution video
sequence S, at high frame rate l, containing the
high-resolution details and the low-resolution motion dynamics. A
motion evaluation algorithm is used to evaluate pixel motion in a
coarse manner between the last interpolated (synthesized) high-resolution
frame St-1 and the current low-resolution frame
Lt generated by the camera.
 Automated Door Attendant
Automated Door Attendant
The ADA is an interactive agent that
serves the role of a simplified secretary, tailored for a university
environment. The agent greets visitors, with a "talking head," takes
messages, schedules appointments, and allows the browsing of selected
documents. Components includes a video monitor, speaker, microphone,
and camera. The attendant is presently being augmented with an
animated face that allows for dynamic control of its movement in order
to simulate the acts of speaking, turning to look in the direction of
a visitor, and even yawning. We wish to carry out such control of the
head as appropriate to the activity currently taking place.
Peripheral Communications
We consider two problems related to communication between
geographically distributed family members. First, we examine the
problem of supporting peripheral awareness, in order to improve both
emotional well-being and awareness of family activity. This is based
on a field study to determine the role and importance of various
peripheral cues in different aspects of everyday activities. The
results from the study were used to guide the design of our proposed
augmented communications environment. Second, we consider the choice
of mechanism to facilitate the on-demand transition to foreground
communication in such an environment. The design suggests an expansion
of Buxton's taxonomy of foreground and background interaction
technologies to encompass a third class of peripheral communications.
 Disparity from contour for object segmentation with occlusion
Disparity from contour for object segmentation with occlusion
A new disparity-based segmentation method is proposed that explores
the static 3D geometry of a background, and produces
disparity-embedded object contours which can be used to separate
objects via a multi-histogram scheme. This method does not require
identical cameras or frame by frame full stereo reconstruction. It has
low computational cost and can be applied to various vision
applications that require object segmentation as a first step
processing. The experiment results show that the proposed method is
able to segment multiple objects despite occlusions.
 Hierarchical Image Coding and Region of Interest Selection
Hierarchical Image Coding and Region of Interest Selection
We are developing low-complexity hierarchical encoding algorithms
that provide modest data reduction at low cost for transmission over
computer networks. A key feature is that the encoding is progressive,
permitting truncation of the data stream at an arbitrary position with
reduction in image quality rather than loss of content. On a related
theme, we note that transmission of the entire data content of a video
stream does not take into account the potentially diverse interests or
capabilities of heterogeneous clients nor the relative importance of
different components of the scene. Assuming operation on a multicast
network, the challenge here is to ensure that individual client requests
are balanced against overall system constraints, such as total available
server bandwidth and limit of multicast channels. Our long-term goal
is for such region selection to be automated with the assistance of
intelligent agents, possibly given some hints from the user, for example,
"I'm interested in this person's face" or "follow that object."
Interaction Paradigms in a Large Screen Environment
Virtual interaction metaphors for two-handed control have been studied in
the past primarily in terms of speed and efficiency. We concentrate our
analysis instead on the cognitive effects such metaphors have on users
within a large screen environment. Based on a series of experiments we
determine how best to manage the division of labour between hands in
order to minimize conceptual error. Empirical evidence suggests that the
proficiency of bimanual paradigms, such as toolglasses or pieglasses,
varies according to a number of factors, for instance the amount of
effort required by the non-preferred hand.
 Parsing and Interpreting Gestures in a Multimodal Virtual Environment
Parsing and Interpreting Gestures in a Multimodal Virtual Environment
Human-computer interaction based on the traditional input mode of
keyboard and mouse fails to scale to the demands of large immersive
environments, where users may be standing and moving about the space.
Instead, we propose a gestural interaction paradigm in which users employ
physical gestures to commmunicate their intentions. We are developing a
framework for the acquisition and parsing of such gestures, using input
from either video camera, data glove, or computer mouse (as a prototype).
The architecture is fully configurable through XML files and uses a
common data type in order to facilitate integration with other software
components distributed over the network.
![]() Statistical Multi-Object Tracking
Statistical Multi-Object Tracking
We are developing a generic object tracker capable of following,
in real-time, multiple objects in a dynamic, real-world, possibly
cluttered environment, in which lighting levels can change dramatically,
for example, a classroom where the instructor walks in front of a
projection screen. Our tracker uses a combination of movement
detection and statistical feature extraction to locate and maintain
objects within the camera's field of view. A final step matches
the various features found in the current image with the objects
previously identified by the system.
 Hand and Fingertip Tracking for Gesture Recognition
Hand and Fingertip Tracking for Gesture Recognition
In augmented reality environments, traditional input interfaces such
as the keyboard-mouse combination are no longer adequate. We turn,
instead, to gestural language, long an important component of human
interaction, employing computer vision techniques to perform hand
tracking and gesture recognition. Our approach employs edge detection
for foreground segmentation and tracks the wrist location with a particle
filter. Based on the wrist location and orientation, we then determine
the positions of the fingertips, exploiting their semi-circular shape by
modelling the fingertip extremities as a circular arc. The fingertips can
be located by looking for maximal responses of a circular Hough transform,
applied to the hand boundary image, followed by several heuristic tests
to filter out false positives and duplicate detection.
 Stochastic Parsing with Semantic Constraints in Multimodal Interaction
Stochastic Parsing with Semantic Constraints in Multimodal Interaction
This project uses typed feature structures and syntactic/semantic
constraints to interpret user actions through arbitrary modes such as
speech, gesture, and handwriting. To this end we have developed a unique
parsing algorithm that takes advantage of this approach to search
through partially specified hierarchical descriptions of user activity.
This algorithm is the core of a larger multimodal framework that can
generically incorporate many existing techniques in multimodal
interaction such as temporal constraints, prosodic effects, and dialogue
management. We intend to demonstrate these capabilities in a handful of
applications, among them a simple multimodal game and a multimodal map
navigation system.
 Parallel Distributed Camera Arrays
Parallel Distributed Camera Arrays
To provide more robust and efficient object tracking for Intelligent
Environments, we are working with colleagues to create a set of
networked low-cost camera arrays that collectively provide high
resolution and large field-of-view image processing capabilities.
Our approach involves the development of a number of novel technologies,
such as smart cameras with on-board reconfigurable image processing
and network communication capabilities, techniques for cooperative
parallel distributed image processing that are suitable for
multi-camera image data, and techniques for reconstruction of
arbitrary viewpoints from a network of video cameras viewing a
scene. Our present efforts are aimed at developing algorithms to
support an array of cameras for parallel distributed processing of
image sequences. This involves synchronized video acquisition,
monocular processing of the individual images, stereo processing
of nearby pairs, matching and triangulation for depth extraction,
and finally, integration of the stereo information from multiple
pairs to generate a rich model of the objects.
 Camera Calibration Methods
Camera Calibration Methods
We conducted a thorough study investigating the effects of training
data quantity, pixel coordinate noise, training data measurement
error, and the choice of camera model on camera calibration results.
The study includes a detailed comparison of various camera models, in
order to determine the relative importance of the various radial and
decentering distortion coefficients. While Tsai's world-reference based
method yielded the most accurate results when trained on data of low
measurement error, this, however, is difficult to achieve in practice
without an expensive and time-consuming setup. In contrast, Zhang's
planar calibration method, although sensitive to noise in training data,
requires only relative measurements between adjacent calibration points,
which can be accomplished accurately with trivial effort, suggesting
that in the absence of sophisticated measurement apparatus, this may
easily outperform Tsai's method.
 Recording Studio that Spans a Continent
Recording Studio that Spans a Continent
On Saturday September 23, 2000, a jazz group performed in a concert hall at
McGill University in Montreal and the recording engineers mixing the
12 channels of audio during the performance were not in a booth at the
back of the hall, but rather in a theatre at the University of Southern
California in Los Angeles.
 Intelligent Classroom Project
Intelligent Classroom Project
Classroom presentation technology was augmented with sensors, wired
to computers for context-sensitive processing. Now, rather than
require manual control, the room activates and configures the
appropriate equipment automatically, in response to instructor
activity. For example, when an instructor logs on to the computer,
the system infers that a lecture is being started, automatically
turns off the lights, lowers the screen, turns on the projector,
and switches the projector to computer input. The simple act of
placing an overhead transparency on the document viewer causes the
slide to be displayed and the room lights adjusted to an appropriate
level. Similarly, audiovisual sources such as the VCR or laptop
computer output are displayed automatically in response to activation
cues. Together, these mechanisms assume the role of skilled
operator, taking responsibility for the low-level control of
the technology, thereby freeing the instructor to concentrate on
the lecture itself, rather than the user interface.
 RoboCup Legged Competition
RoboCup Legged Competition
From 1999 through 2002, McGill was the only Canadian university
and one of only four North American schools to participate in the
Sony Legged league of the
RoboCup Competition. This competition pitted our Sony legged robots against
teams from other universities in a "cat-eat-cat" test of artificial
intelligence and soccers skills.
 Phidgets Interface
Phidgets Interface
Based on the work of
Greenberg and Fitchett, a project group designed and
prototyped an elegant, USB-based I/O system to allow for easy and rapid
development of software that interfaces to analog and digital inputs,
digital outputs, and stepper motor control. The software environment
surrounding this system was initially limited to running under Visual
Basic on Windows systems but we are now extending the libraries with
more advanced graphical capabilities and porting the system to Linux.
GraffitiBoard
The GraffitiBoard is a wall-sized computer display that tracks the
position of a pointer (such as a user's finger) and displays the
resulting penstrokes as if the user were writing on the wall. A
video projector produces the displayed image while a video camera
captures the users' actions. By applying a simple colour tracking
algorithm or a more complex cross-correlation technique, it is
possible to recognize certain actions and respond accordingly. For
example, if the user's hand is placed on the wall, a palette with various painting options
can be generated at that location. For our demostration program,
we use both colour tracking and correlation techniques to track the
movement of user's finger and draw
and pictures and letters.
This project uses speech recognition software and video overlay text
messages to provide an intuitive VCR interface. Current projects
include rebuilding a perl script that generates an electronic TV guide
from the web, improving the grammar to deal with context-sensitive help,
and running a formal experiment comparing the UbiVCR with other VCR-programming
methods.
Millenium Exhibit
This project involved the development of two components of a
fictitious house of the future for the Ontario Science Center.
The exhibit consists of a dining room
and living room scenario. Each room
reacts to user activity, utilizing information from video cameras,
voice recognition, and various low-level sensors, providing output
through synthesized speech, audio and video clips.
Reactive Room
This project (1993-1995) developed a state of the art videoconferencing facility, augmented with various
sensors, which reacted to user activity by automatically selecting
appropriate configurations of audio and video sources. The system
infers the intentions of users and reacts accordingly, allowing
them to conduct both local and videoconference meetings, making
full use of the presentation technology (document camera, VCR,
digital whiteboard) without needing to interact with the computer.
Adaptive File
Distribtion Protocol
AFDP is a protocol for the efficient and reliable distribution of large
files to many hosts on a LAN or internetwork. The protocol is built on
top of UDP, and uses a rate-based flow control mechanism following the
publishing metaphor.
 NOVICE: Neural network robotic control
NOVICE: Neural network robotic control
A robotic system using simple visual processing and controlled by
neural networks was developed. The robot performs docking and target
reaching without prior geometric calibration of its components. All
effects of control signals on the robot are learned by the controller
through visual observation during a training period, and refined during
actual operation. Minor changes in the system's configuration result
in a brief period of degraded performance while the controller adapts
to the new mappings.

Last update: 2 June 2024